
 Felix Kleinsteuber
Felix Kleinsteuber
41 измененных файлов с 190 добавлено и 67 удалено
Разница между файлами не показана из-за своего большого размера
+ 5
- 17
approach1a_basic_frame_differencing.ipynb
Разница между файлами не показана из-за своего большого размера
+ 8
- 11
approach2_background_estimation.ipynb
Разница между файлами не показана из-за своего большого размера
+ 2
- 4
approach3_local_features.ipynb
Разница между файлами не показана из-за своего большого размера
+ 16
- 6
approach4_autoencoder.ipynb
+ 9
- 6
eval_bow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
plots/approach1a/roc_curves/Beaver_01_absmean.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_absmean.png
{kind=link}
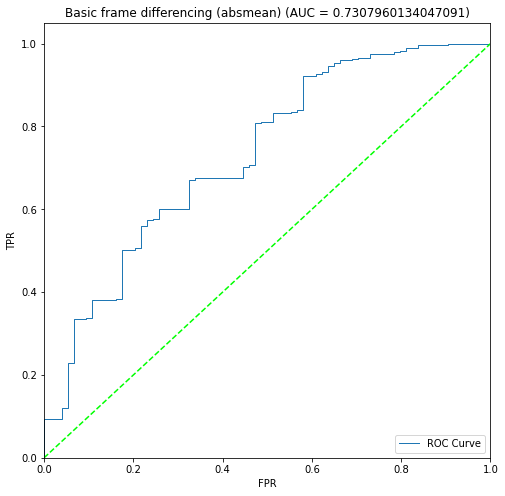
BIN
plots/approach1a/roc_curves/Beaver_01_absmean_sigma2.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_absmean_sigma2.png
{kind=link}
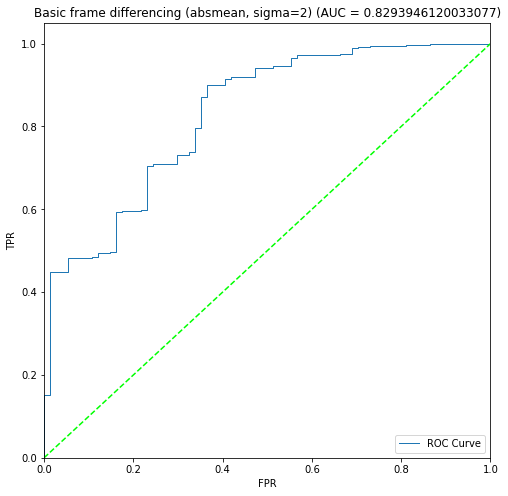
BIN
plots/approach1a/roc_curves/Beaver_01_absvar.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_absvar.png
{kind=link}
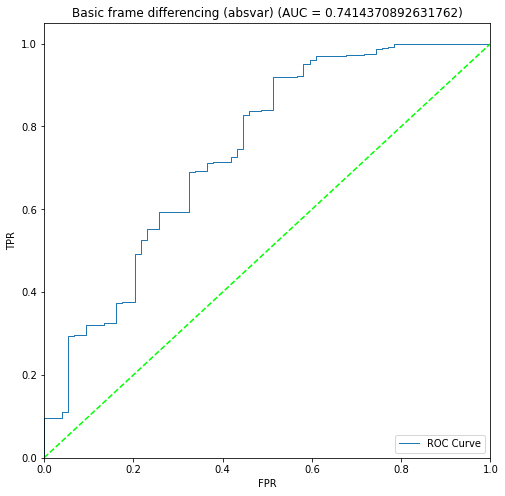
BIN
plots/approach1a/roc_curves/Beaver_01_absvar_sigma2.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_absvar_sigma2.png
{kind=link}
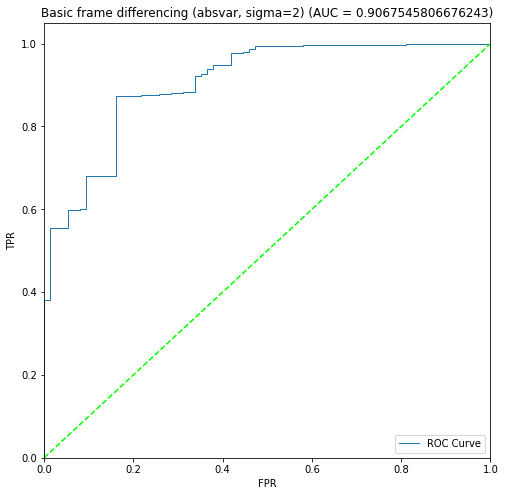
BIN
plots/approach1a/roc_curves/Beaver_01_sqmean.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_sqmean.png
{kind=link}
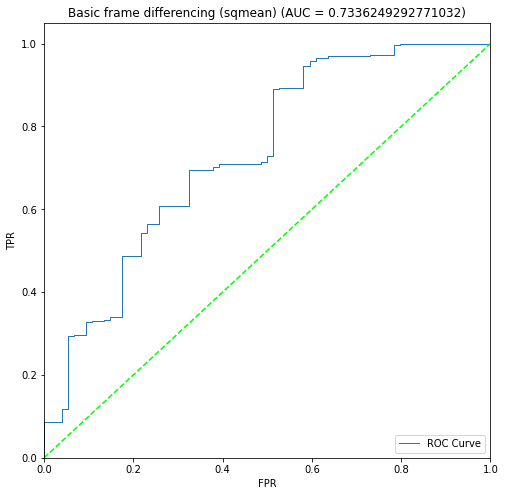
BIN
plots/approach1a/roc_curves/Beaver_01_sqmean_sigma2.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_sqmean_sigma2.png
{kind=link}

BIN
plots/approach1a/roc_curves/Beaver_01_sqvar.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_sqvar.png
{kind=link}

BIN
plots/approach1a/roc_curves/Beaver_01_sqvar_sigma2.pdf
BIN
plots/approach1a/roc_curves/Beaver_01_sqvar_sigma2.png
{kind=link}
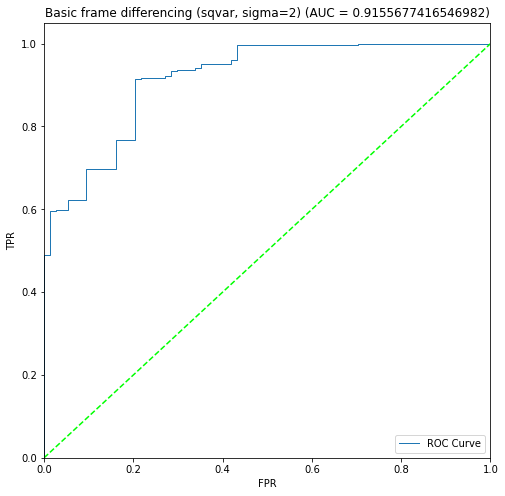
BIN
plots/approach2/roc_curves/Beaver_01_sqmean.pdf
BIN
plots/approach2/roc_curves/Beaver_01_sqmean_sigma2.pdf
BIN
plots/approach2/roc_curves/Beaver_01_sqmean_sigma4.pdf
BIN
plots/approach2/roc_curves/Beaver_01_sqvar.pdf
BIN
plots/approach2/roc_curves/Beaver_01_sqvar_sigma2.pdf
BIN
plots/approach2/roc_curves/Beaver_01_sqvar_sigma4.pdf
BIN
plots/approach3/roc_curves/Beaver_01_30_30_1024.pdf
BIN
plots/approach3/roc_curves/Beaver_01_30_30_1024.png
{kind=link}

BIN
plots/approach3/roc_curves/Beaver_01_30_30_2048.pdf
BIN
plots/approach3/roc_curves/Beaver_01_30_40_1024.pdf
BIN
plots/approach3/roc_curves/Beaver_01_30_40_1024.png
{kind=link}
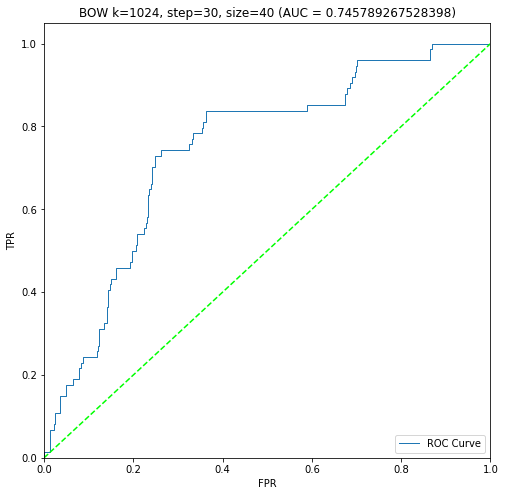
BIN
plots/approach4/roc_curves/Beaver_01_kde,loss.pdf
BIN
plots/approach4/roc_curves/Beaver_01_kde.pdf
BIN
plots/approach4/roc_curves/Beaver_01_loss.pdf
+ 1
- 0
py/FileUtils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Разница между файлами не показана из-за своего большого размера
+ 0
- 3
py/Labels.py
+ 9
- 2
py/LocalFeatures.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 60
- 0
quick_label.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 36
- 10
results.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 44
- 8
train_bow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||