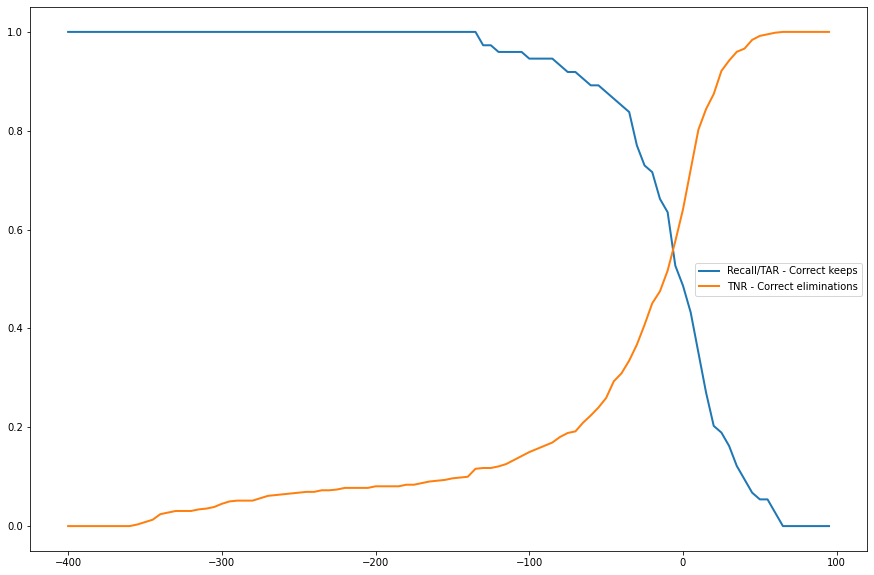
|
|
@@ -0,0 +1,87 @@
|
|
|
+import argparse
|
|
|
+import os
|
|
|
+from tqdm import tqdm
|
|
|
+import torch
|
|
|
+from torch import nn
|
|
|
+from torch.autograd import Variable
|
|
|
+from torch.utils.data import DataLoader
|
|
|
+from torchvision.utils import save_image
|
|
|
+from torchinfo import summary
|
|
|
+
|
|
|
+from py.PyTorchData import create_dataloader, model_output_to_image
|
|
|
+from py.Autoencoder2 import Autoencoder
|
|
|
+
|
|
|
+def train_autoencoder(model: nn.Module, train_dataloader: DataLoader, name: str, device: str = "cpu", num_epochs=100, criterion = nn.MSELoss(), lr: float = 1e-3, weight_decay: float = 1e-5, noise: bool = False):
|
|
|
+ model = model.to(device)
|
|
|
+ print(f"Using {device} device")
|
|
|
+ optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
|
|
|
+
|
|
|
+ print(f"Saving models to ./ae_train_NoBackup/{name}")
|
|
|
+ os.makedirs(f"./ae_train_NoBackup/{name}", exist_ok=True)
|
|
|
+
|
|
|
+ print(f"Training for {num_epochs} epochs.")
|
|
|
+ for epoch in range(num_epochs):
|
|
|
+ total_loss = 0
|
|
|
+ for img, _ in tqdm(train_dataloader):
|
|
|
+
|
|
|
+ img = Variable(img).to(device)
|
|
|
+ input = img
|
|
|
+ if noise:
|
|
|
+ input = input + (0.01 ** 0.5) * torch.randn(img.size(), device=device)
|
|
|
+ # ===================forward=====================
|
|
|
+ output = model(input)
|
|
|
+ loss = criterion(output, img)
|
|
|
+ # ===================backward====================
|
|
|
+ optimizer.zero_grad()
|
|
|
+ loss.backward()
|
|
|
+ optimizer.step()
|
|
|
+ total_loss += loss.data
|
|
|
+ # ===================log========================
|
|
|
+ dsp_epoch = epoch + 1
|
|
|
+ print('epoch [{}/{}], loss:{:.4f}'.format(dsp_epoch, num_epochs, total_loss))
|
|
|
+
|
|
|
+ # log file
|
|
|
+ with open(f"./ae_train_NoBackup/{name}/log.csv", "a+") as f:
|
|
|
+ f.write(f"{dsp_epoch},{total_loss}\n")
|
|
|
+
|
|
|
+ # output image
|
|
|
+ if epoch % 2 == 0:
|
|
|
+ pic = model_output_to_image(output.cpu().data)
|
|
|
+ save_image(pic, f"./ae_train_NoBackup/{name}/image_{dsp_epoch:03d}.png")
|
|
|
+
|
|
|
+ # model checkpoint
|
|
|
+ if epoch % 5 == 0:
|
|
|
+ torch.save(model.state_dict(), f"./ae_train_NoBackup/{name}/model_{dsp_epoch:03d}.pth")
|
|
|
+
|
|
|
+ torch.save(model.state_dict(), f"./ae_train_NoBackup/{name}/model_{num_epochs:03d}.pth")
|
|
|
+
|
|
|
+
|
|
|
+if __name__ == "__main__":
|
|
|
+ parser = argparse.ArgumentParser(description="Autoencoder train script")
|
|
|
+ parser.add_argument("name", type=str, help="Name of the training session (name of the save folder)")
|
|
|
+ parser.add_argument("img_folder", type=str, help="Path to directory containing train images (may contain subfolders)")
|
|
|
+ parser.add_argument("--device", type=str, help="PyTorch device to train on (cpu or cuda)", default="cpu")
|
|
|
+ parser.add_argument("--epochs", type=int, help="Number of epochs", default=100)
|
|
|
+ parser.add_argument("--batch_size", type=int, help="Batch size (>=1)", default=32)
|
|
|
+ parser.add_argument("--lr", type=float, help="Learning rate", default=1e-3)
|
|
|
+ parser.add_argument("--image_transforms", action="store_true", help="Truncate and resize images (only enable if the input images have not been truncated resized to the target size already)")
|
|
|
+ parser.add_argument("--noise", action="store_true", help="Add Gaussian noise to model input")
|
|
|
+
|
|
|
+ args = parser.parse_args()
|
|
|
+
|
|
|
+ if args.image_transforms:
|
|
|
+ print("Image transforms enabled: Images will be truncated and resized.")
|
|
|
+ else:
|
|
|
+ print("Image transforms disabled: Images are expected to be of the right size.")
|
|
|
+
|
|
|
+ data_loader = create_dataloader(args.img_folder, batch_size=args.batch_size, skip_transforms=not args.image_transforms)
|
|
|
+ model = Autoencoder()
|
|
|
+ print("Model:")
|
|
|
+ summary(model, (args.batch_size, 3, 256, 256))
|
|
|
+ print("Is CUDA available:", torch.cuda.is_available())
|
|
|
+ print(f"Devices: ({torch.cuda.device_count()})")
|
|
|
+ for i in range(torch.cuda.device_count()):
|
|
|
+ print(torch.cuda.get_device_name(i))
|
|
|
+ if args.noise:
|
|
|
+ print("Adding Gaussian noise to model input")
|
|
|
+ train_autoencoder(model, data_loader, args.name, device=args.device, num_epochs=args.epochs, lr=args.lr, noise=args.noise)
|

 Felix Kleinsteuber
Felix Kleinsteuber
{kind=link}
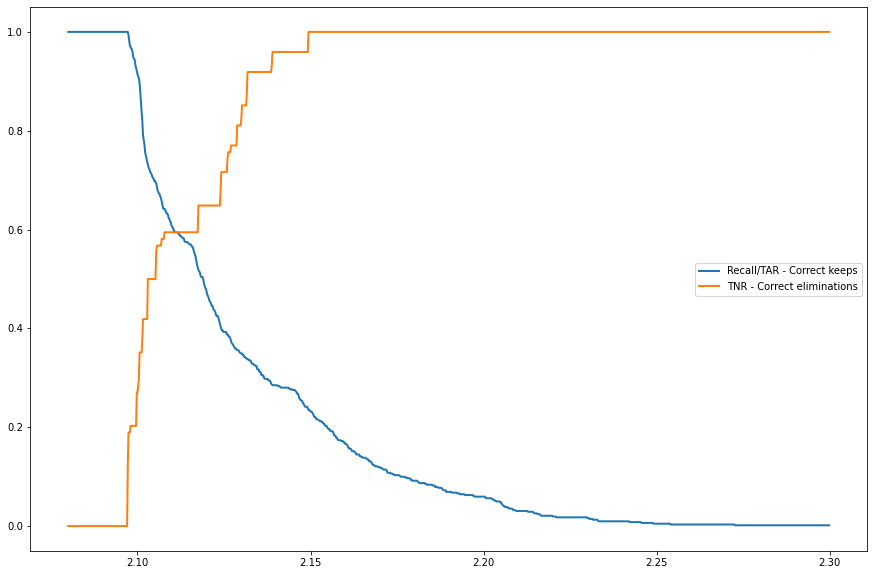
{kind=link}
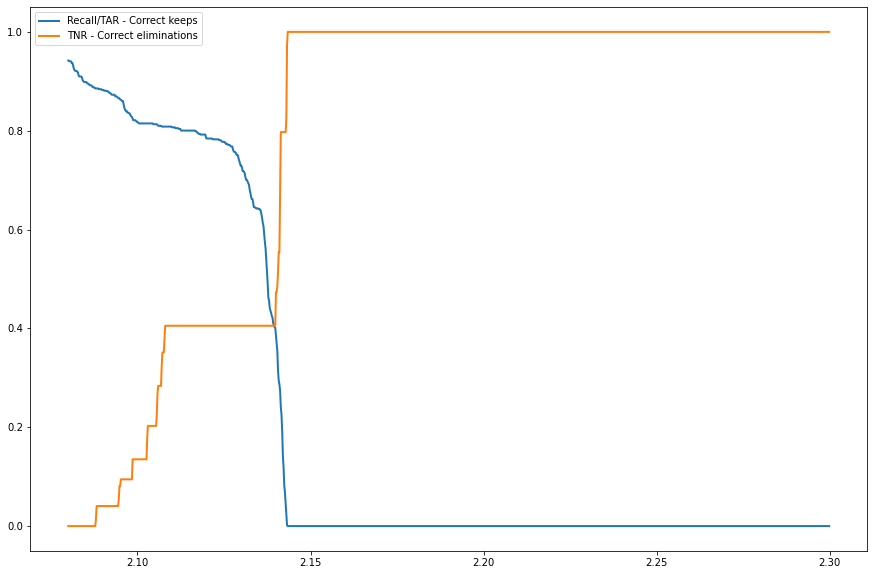
{kind=link}

{kind=link}
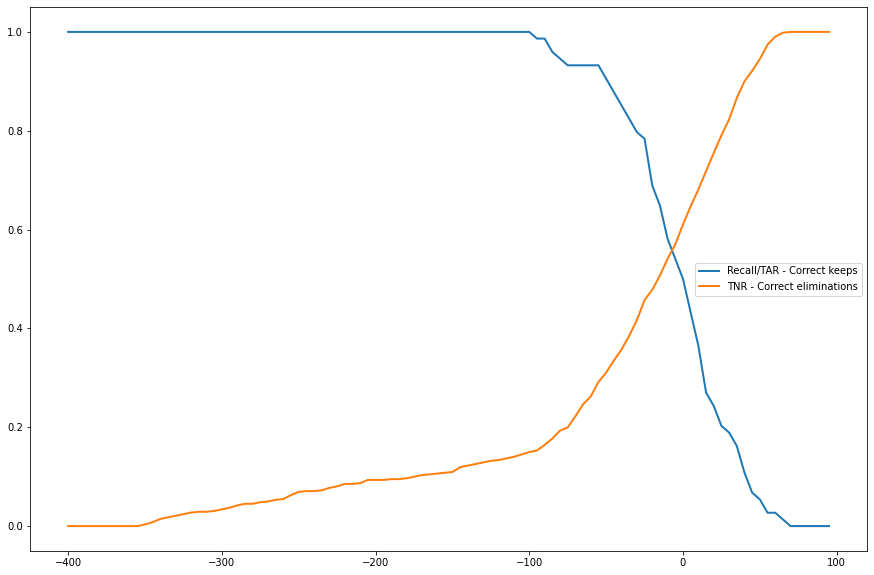
{kind=link}

{kind=link}