
 Felix Kleinsteuber
Felix Kleinsteuber
File diff suppressed because it is too large
+ 15
- 22
approach1a_basic_frame_differencing.ipynb
File diff suppressed because it is too large
+ 24
- 23
approach2_background_estimation.ipynb
二進制
approach2_results.npy
File diff suppressed because it is too large
+ 5
- 6
approach3_local_features.ipynb
File diff suppressed because it is too large
+ 36
- 138
approach4_autoencoder.ipynb
+ 5
- 4
eval_bow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
二進制
plots/approach1a/roc_curves/Beaver_01.pdf
二進制
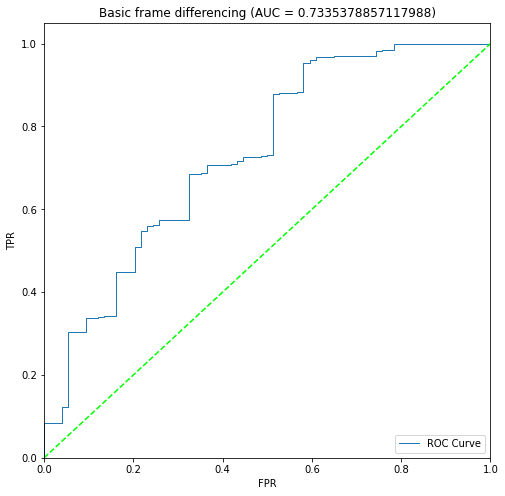
plots/approach1a/roc_curves/Beaver_01.png
{kind=link}
二進制
plots/approach1a/roc_curves/Beaver_01_sigma2.pdf
二進制
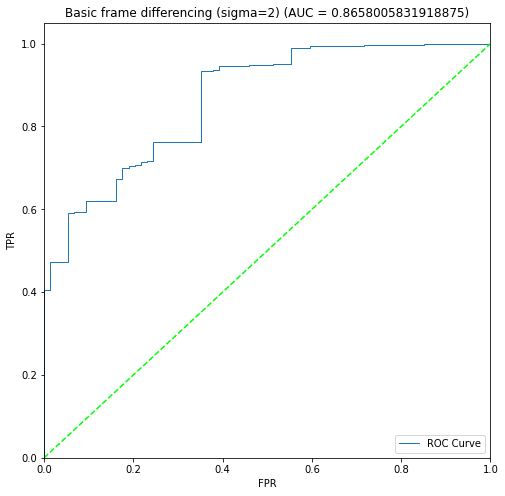
plots/approach1a/roc_curves/Beaver_01_sigma2.png
{kind=link}
二進制
plots/approach1a/roc_curves/Beaver_01_sigma4.pdf
二進制
plots/approach1a/roc_curves/Beaver_01_sigma4.png
{kind=link}

二進制
plots/approach2/roc_curves/Beaver_01.pdf
二進制
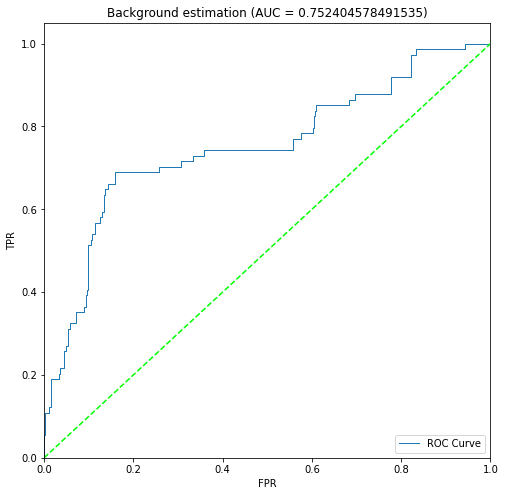
plots/approach2/roc_curves/Beaver_01.png
{kind=link}
二進制
plots/approach2/roc_curves/Marten_01.pdf
二進制
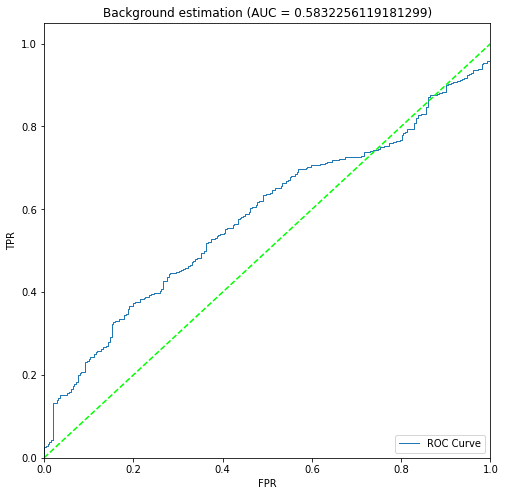
plots/approach2/roc_curves/Marten_01.png
{kind=link}
+ 0
- 0
plots/approach3/beaver_01_bow_1024_tar_vs_tnr.png → plots/approach3/beaver_01_bow_1024_30_tar_vs_tnr.png
{kind=link}

+ 0
- 0
plots/approach3/beaver_01_bow_2048_tar_vs_tnr.png → plots/approach3/beaver_01_bow_2048_30_tar_vs_tnr.png
{kind=link}

+ 0
- 0
plots/approach3/beaver_01_bow_512_tar_vs_tnr.png → plots/approach3/beaver_01_bow_512_30_tar_vs_tnr.png
{kind=link}

+ 0
- 0
plots/approach3/marten_01_bow_1024_tar_vs_tnr.png → plots/approach3/marten_01_bow_1024_30_tar_vs_tnr.png
{kind=link}

+ 0
- 0
plots/approach3/marten_01_bow_2048_tar_vs_tnr.png → plots/approach3/marten_01_bow_2048_30_tar_vs_tnr.png
{kind=link}
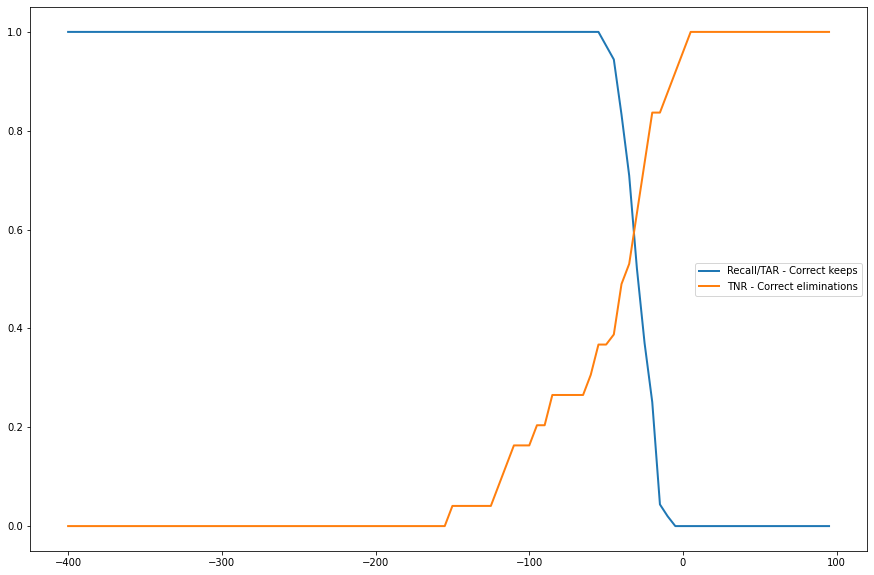
+ 0
- 0
plots/approach3/marten_01_bow_512_tar_vs_tnr.png → plots/approach3/marten_01_bow_512_30_tar_vs_tnr.png
{kind=link}

二進制
plots/approach3/roc_curves/Beaver_01_20_1024.pdf
二進制
plots/approach3/roc_curves/Beaver_01_20_1024.png
{kind=link}
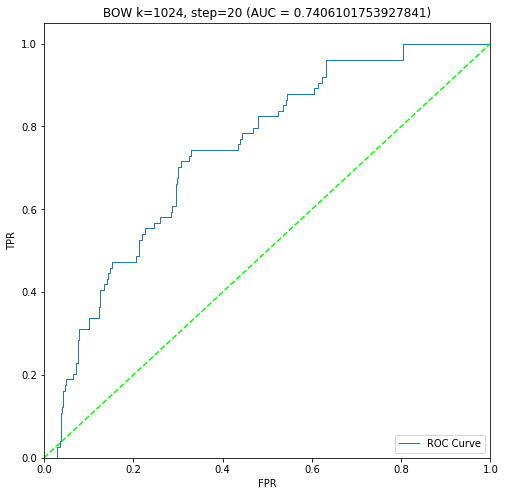
二進制
plots/approach3/roc_curves/Beaver_01_30_1024.pdf
二進制
plots/approach3/roc_curves/Beaver_01_30_1024.png
{kind=link}
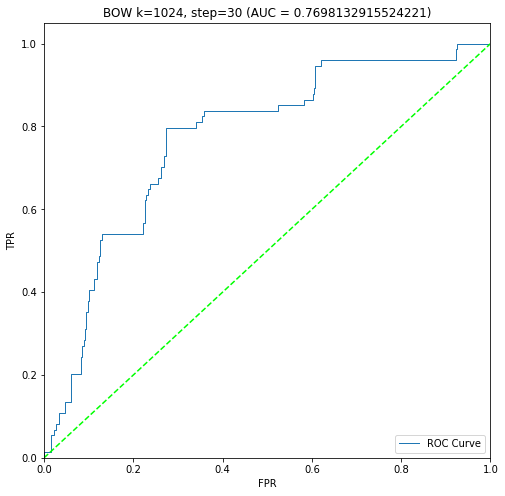
二進制
plots/approach3/roc_curves/Beaver_01_30_2048.pdf
二進制
plots/approach3/roc_curves/Beaver_01_30_2048.png
{kind=link}

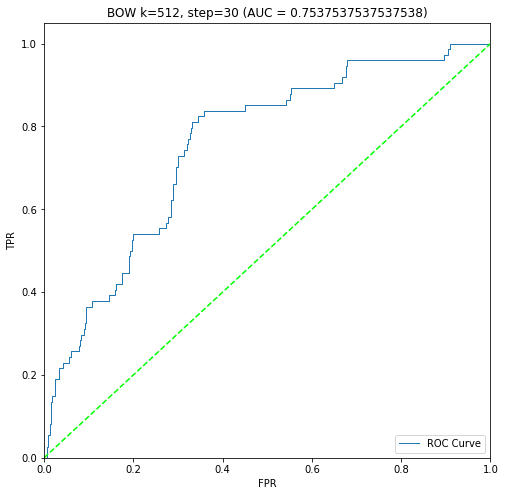
二進制
plots/approach3/roc_curves/Beaver_01_30_512.pdf
二進制
plots/approach3/roc_curves/Beaver_01_30_512.png
{kind=link}
二進制
plots/approach3/roc_curves/Marten_01_30_1024.pdf
二進制
plots/approach3/roc_curves/Marten_01_30_1024.png
{kind=link}

二進制
plots/approach3/roc_curves/Marten_01_30_2048.pdf
二進制
plots/approach3/roc_curves/Marten_01_30_2048.png
{kind=link}

二進制
plots/approach3/roc_curves/Marten_01_30_512.pdf
二進制
plots/approach3/roc_curves/Marten_01_30_512.png
{kind=link}
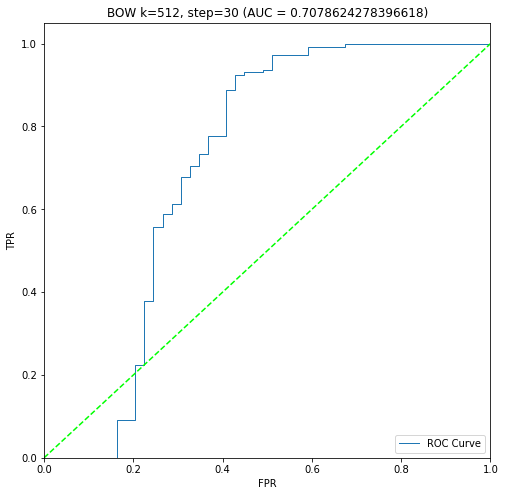
二進制
plots/approach4/roc_curves/Beaver_01_kde,loss.pdf
二進制
plots/approach4/roc_curves/Beaver_01_kde,loss.png
{kind=link}
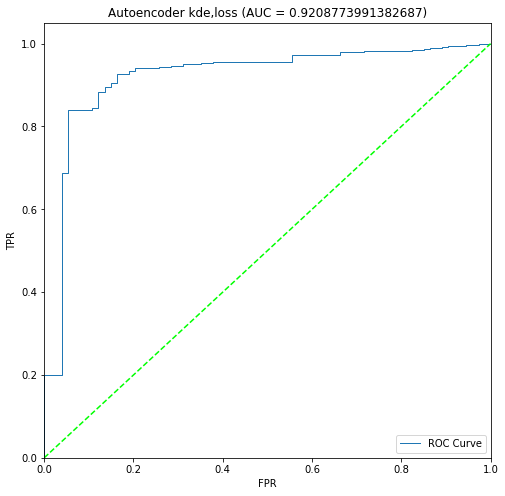
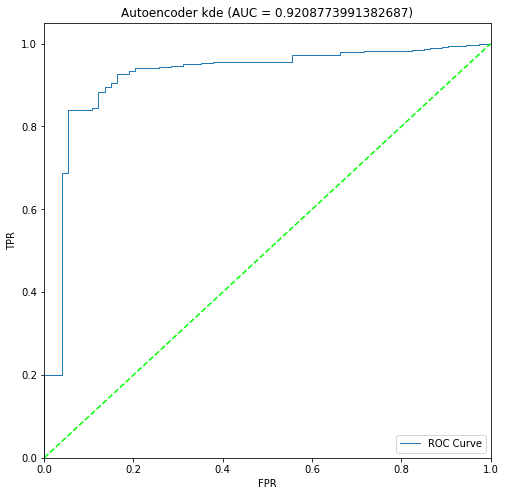
二進制
plots/approach4/roc_curves/Beaver_01_kde.pdf
二進制
plots/approach4/roc_curves/Beaver_01_kde.png
{kind=link}
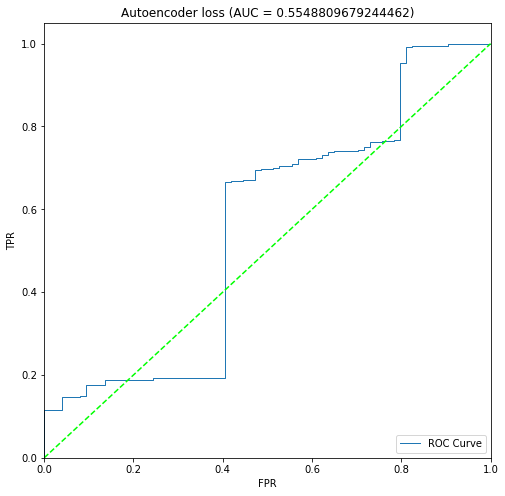
二進制
plots/approach4/roc_curves/Beaver_01_loss.pdf
二進制
plots/approach4/roc_curves/Beaver_01_loss.png
{kind=link}
二進制
plots/approach4/roc_curves/Marten_01_kde,loss.pdf
二進制
plots/approach4/roc_curves/Marten_01_kde,loss.png
{kind=link}

二進制
plots/approach4/roc_curves/Marten_01_kde.pdf
二進制
plots/approach4/roc_curves/Marten_01_kde.png
{kind=link}

二進制
plots/approach4/roc_curves/Marten_01_loss.pdf
二進制
plots/approach4/roc_curves/Marten_01_loss.png
{kind=link}
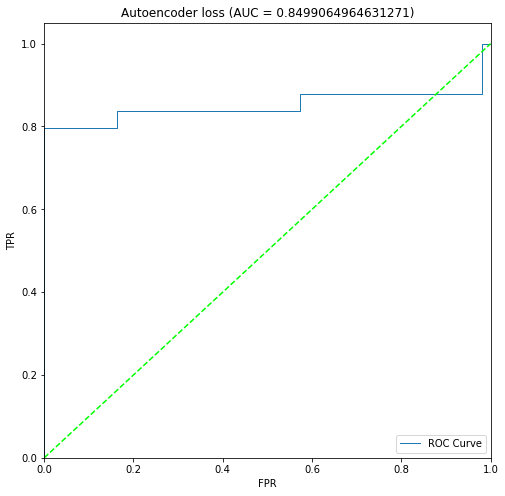
+ 16
- 7
py/LocalFeatures.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 21
- 0
py/PlotUtils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 2
- 2
py/Session.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 54
- 0
results.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 5
train_bow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||