
README.md 4.4 KB
Fine-Tune Framework based on Chainer
Chainer framework is an easy to use DL framework. It is designed in a hierarchical manner and provides usefull implementations for all of the parts required to train a network:
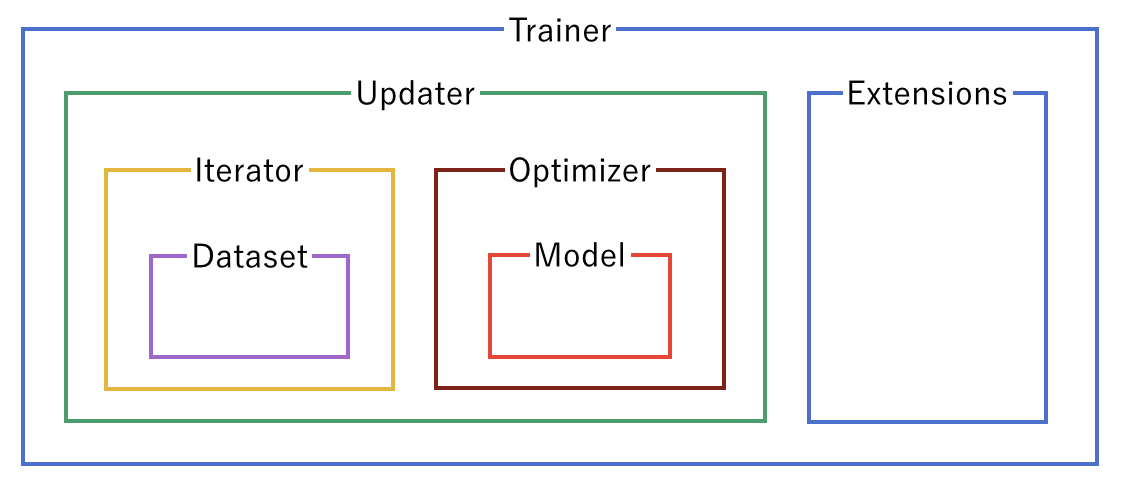
We developed cvmodelz for fast and easy way of initializing commonly used models ("Model" box), and cvdatasets provides methods to load dataset annotations and create a dataset object ("Dataset" box) that can be further passed to the iterator.
An example training script might be looking like this:
#!/usr/bin/env python
if __name__ != '__main__': raise Exception("Do not import me!")
import chainer as ch
from chainer import training
from chainer.training import extensions
from cvargparse import GPUParser
from cvargparse import Arg
from cvdatasets import FileListAnnotations
from cvdatasets import Dataset as BaseDataset
from cvmodelz.models import ModelFactory
from cvmodelz.classifiers import Classifier
class Dataset(BaseDataset):
def __init__(self, *args, prepare, **kw):
super().__init__(*args, **kw)
self._prepare = prepare
def get_example(self, i):
im, _, label = super().get_example(i)
im = self._prepare(im, size=(224, 224))
return im, label
def main(args):
model = ModelFactory.new(args.model_type)
clf = Classifier(model)
device = ch.get_device(args.gpu[0])
device.use()
annot = FileListAnnotations(root_or_infofile=args.data_root)
train, test = annot.new_train_test_datasets(
dataset_cls=Dataset, prepare=model.prepare)
train_iter = ch.iterators.MultiprocessIterator(train, batch_size=32, n_processes=4)
test_iter = ch.iterators.MultiprocessIterator(test, batch_size=32, n_processes=4,
repeat=False, shuffle=False)
# Setup an optimizer
optimizer = ch.optimizers.AdamW(alpha=1e-3).setup(clf)
# Create the updater, using the optimizer
updater = training.StandardUpdater(train_iter, optimizer, device=device)
# Set up a trainer
trainer = training.Trainer(updater, (50, 'epoch'), out='result')
# Evaluate the model with the test dataset for each epoch
trainer.extend(extensions.Evaluator(test_iter, clf,
progress_bar=True,
device=device))
trainer.extend(extensions.ProgressBar(update_interval=1))
# Write a log of evaluation statistics for each epoch
trainer.extend(extensions.LogReport())
# Print selected entries of the log to stdout
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss',
'main/accuracy', 'validation/main/accuracy']))
# Run the training
trainer.run()
parser = GPUParser([
Arg("data_root"),
Arg("model_type", choices=ModelFactory.get_models(["cvmodelz"])),
])
main(parser.parse_args())
# start it with 'python train.py path/to/dataset cvmodelz.ResNet50'
Everything after the first two lines in the main function is chainer-related and has to be done every time one needs to write an experiment.
Hence, cvfinetune simplifies everything and abstracts the initializations:
from chainer.training.updaters import StandardUpdater
from cvfinetune.finetuner import FinetunerFactory
from cvfinetune.training.trainer import Trainer
from cvfinetune.parser import default_factory
from cvfinetune.parser import FineTuneParser
from cvmodelz.classifiers import Classifier
from cvdatasets.dataset import AnnotationsReadMixin
from cvdatasets.dataset import TransformMixin
parser = FineTuneParser(default_factory())
class Dataset(TransformMixin, AnnotationsReadMixin):
def __init__(self, *args, prepare, center_crop_on_val: bool = True, **kwargs):
super().__init__(*args, **kwargs)
self.prepare = prepare
self.center_crop_on_val = center_crop_on_val
def transform(self, im_obj):
im, parts, lab = im_obj.as_tuple()
return self.prepare(im), lab + self.label_shift
def main(args):
factory = FinetunerFactory(mpi=False)
tuner = factory(args,
classifier_cls=Classifier,
dataset_cls=Dataset,
updater_cls=StandardUpdater,
no_sacred=True,
)
tuner.run(trainer_cls=Trainer, opts=args)
main(parser.parse_args())