
 Felix Kleinsteuber
Felix Kleinsteuber
66 измененных файлов с 618 добавлено и 25 удалено
BIN
annotations.npy
Разница между файлами не показана из-за своего большого размера
+ 11
- 5
approach1a_basic_frame_differencing.ipynb
BIN
approach1b_results.npy
Разница между файлами не показана из-за своего большого размера
+ 196
- 0
approach3_boxplot.ipynb
Разница между файлами не показана из-за своего большого размера
+ 0
- 0
approach3_local_features.ipynb
BIN
approach4_ae1.png
{kind=link}
BIN
approach4_ae2.png
{kind=link}
BIN
approach4_ae2_noise.png
{kind=link}
Разница между файлами не показана из-за своего большого размера
+ 329
- 0
approach4_boxplot.ipynb
BIN
exp1a_annotations.npy
+ 0
- 0
approach1a_difference_image.png → imgs/approach1a_difference_image.png
{kind=link}

+ 0
- 0
approach1a_difference_image2.png → imgs/approach1a_difference_image2.png
{kind=link}

+ 0
- 0
approach1a_gaussianworksbetter_sigma0.png → imgs/approach1a_gaussianworksbetter_sigma0.png
{kind=link}

+ 0
- 0
approach1a_gaussianworksbetter_sigma4.png → imgs/approach1a_gaussianworksbetter_sigma4.png
{kind=link}

BIN
imgs/approach1a_lapse.pdf
BIN
imgs/approach1a_motion.pdf
BIN
imgs/approach1a_sqdiff.pdf
+ 0
- 0
approach2_bad_example_imgs.png → imgs/approach2_bad_example_imgs.png
{kind=link}

+ 0
- 0
approach2_bad_example_median.png → imgs/approach2_bad_example_median.png
{kind=link}

+ 0
- 0
approach2_good_example_imgs.png → imgs/approach2_good_example_imgs.png
{kind=link}

+ 0
- 0
approach2_good_example_median.png → imgs/approach2_good_example_median.png
{kind=link}

+ 0
- 0
approach3_dsift.png → imgs/approach3_dsift.png
{kind=link}

+ 0
- 0
approach3_keypoints.pdf → imgs/approach3_keypoints.pdf
+ 0
- 0
approach3_keypoints_lapse.pdf → imgs/approach3_keypoints_lapse.pdf
+ 0
- 0
approach4_difficult_anomalous_beaver_01.png → imgs/approach4_difficult_anomalous_beaver_01.png
{kind=link}

+ 0
- 0
approach4_difficult_anomalous_marten_01.png → imgs/approach4_difficult_anomalous_marten_01.png
{kind=link}

+ 0
- 0
approach4_difficult_normal_beaver_01.png → imgs/approach4_difficult_normal_beaver_01.png
{kind=link}

+ 0
- 0
approach4_difficult_normal_marten_01.png → imgs/approach4_difficult_normal_marten_01.png
{kind=link}

+ 0
- 0
approach4_easy_anomalous_beaver_01.png → imgs/approach4_easy_anomalous_beaver_01.png
{kind=link}

+ 0
- 0
approach4_easy_anomalous_marten_01.png → imgs/approach4_easy_anomalous_marten_01.png
{kind=link}

+ 0
- 0
approach4_easy_normal_beaver_01.png → imgs/approach4_easy_normal_beaver_01.png
{kind=link}

+ 0
- 0
approach4_easy_normal_marten_01.png → imgs/approach4_easy_normal_marten_01.png
{kind=link}

+ 0
- 0
approach4_reconstructions.png → imgs/approach4_reconstructions.png
{kind=link}

+ 0
- 0
approach4_reconstructions_beaver01.png → imgs/approach4_reconstructions_beaver01.png
{kind=link}

+ 58
- 0
index.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
plots/approach1a/roc_curves/Marten_01_absmean.pdf
BIN
plots/approach1a/roc_curves/Marten_01_absmean.png
{kind=link}
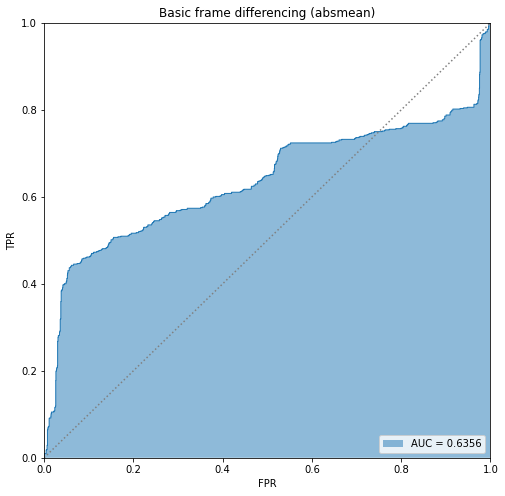
BIN
plots/approach1a/roc_curves/Marten_01_absmean_sigma6.pdf
BIN
plots/approach1a/roc_curves/Marten_01_absmean_sigma6.png
{kind=link}

BIN
plots/approach1a/roc_curves/Marten_01_absvar.pdf
BIN
plots/approach1a/roc_curves/Marten_01_absvar.png
{kind=link}
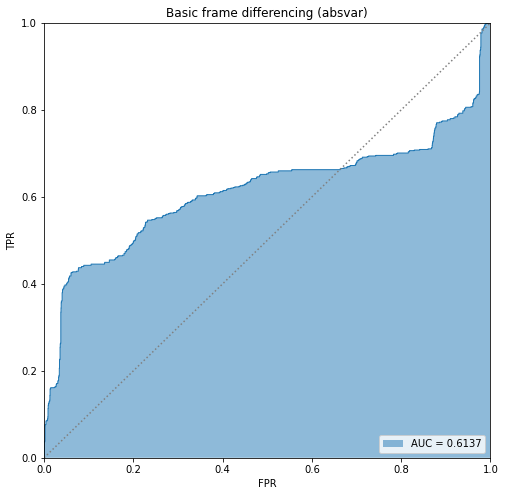
BIN
plots/approach1a/roc_curves/Marten_01_absvar_sigma6.pdf
BIN
plots/approach1a/roc_curves/Marten_01_absvar_sigma6.png
{kind=link}
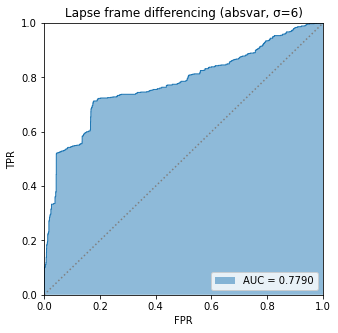
BIN
plots/approach1a/roc_curves/Marten_01_sqmean.pdf
BIN
plots/approach1a/roc_curves/Marten_01_sqmean.png
{kind=link}
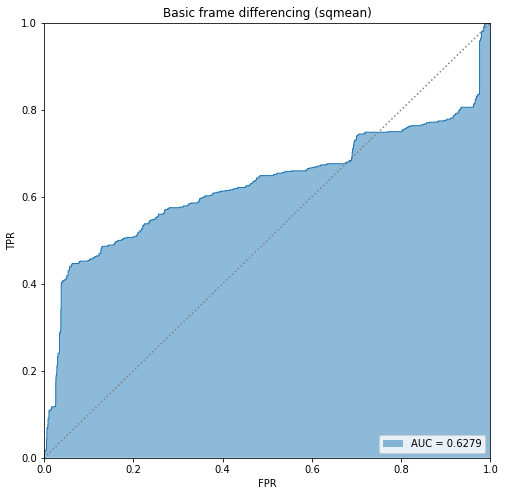
BIN
plots/approach1a/roc_curves/Marten_01_sqmean_sigma6.pdf
BIN
plots/approach1a/roc_curves/Marten_01_sqmean_sigma6.png
{kind=link}
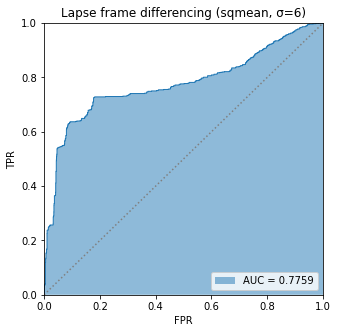
BIN
plots/approach1a/roc_curves/Marten_01_sqvar.pdf
BIN
plots/approach1a/roc_curves/Marten_01_sqvar.png
{kind=link}
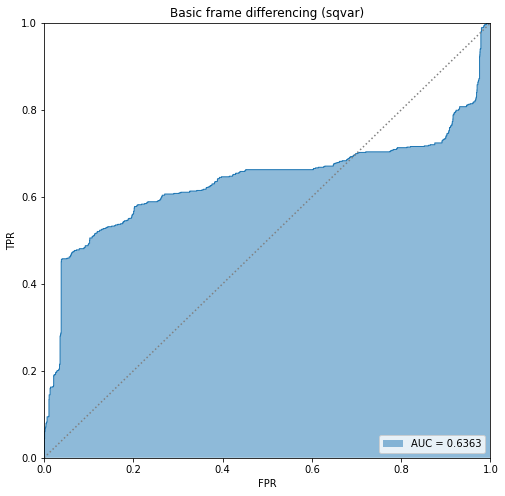
BIN
plots/approach1a/roc_curves/Marten_01_sqvar_sigma6.pdf
BIN
plots/approach1a/roc_curves/Marten_01_sqvar_sigma6.png
{kind=link}
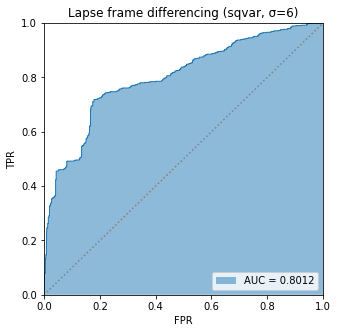
BIN
plots/approach3/boxplot_random.pdf
BIN
plots/approach3/boxplot_random_tnr95.pdf
BIN
plots/approach4/boxplot_kde_denoising.pdf
BIN
plots/approach4/boxplot_kde_denoising_and_sparse.pdf
BIN
plots/approach4/boxplot_kde_denoising_and_sparse_tnr95.pdf
BIN
plots/approach4/boxplot_kde_denoising_tnr95.pdf
BIN
plots/approach4/boxplot_kde_latentfeatures.pdf
BIN
plots/approach4/boxplot_kde_latentfeatures_tnr95.pdf
BIN
plots/approach4/boxplot_kde_sparse.pdf
BIN
plots/approach4/boxplot_kde_sparse_tnr95.pdf
+ 1
- 0
py/ImageUtils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 2
py/PlotUtils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 1
py/Session.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 8
resize_session.ipynb
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 9
train_autoencoder.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||